What is Snowplow - the behavioral data platform?

- Why not using Google Analytics?
- What is Snowplow?
- What's the architecture of Snowplow
- The Snowplow pipeline
- Data modelling
- Feature summary
Knowing how our websites perform is critical for the success of virtually any business in this internet-focussed time. We design and create websites and web apps to satisfy our users, engage them and - at the end - make money. For these reasons it's from elementary importance to know, how our users are behaving on our sites, where they experience struggles and bottlenecks and where and why they churn. To answer all of these - and many more questions, there are numerous web-trackers on the market, from Google Analytics, to Adobe Analytics - and to Snowplow.
Snowplow is the third-most used web tracking solution on the planet - directly after Google Analytics and the Facebook Web-Tracker.
Why not using Google Analytics?
As Google Analytics is the most used tracker - and it's free after all - why not using it?
Unfortunately, Google did a lot of bad things when it comes to Google Analytics:
Google Universal Analytics (UA) - the predecessor of Google Analytics 4 (GA4) - was many times a hit for Google and equally for many website owners. Universal Analytics was easy to integrate, easy to use, and delivered decent results out of the box for data novices. And beginners were exactly the target-group of UA. The product was not intended for experts - and experts did not enjoy it. They didn't have to. Beginners and hobbyists were rightly happy about a free, huge, easy to use and feature-rich web-tracking solution. While UA was a huge success - and also a product which was really recommended to use when looking on what it promised - there was a huge problem: UA was and never will be GDPR compliant. It stores data in America and it's quite easy to identify users based on browser fingerprint, etc.
Several courts determined, that UA is actually illegal to use in Europe. So Google came around with Google Analytics 4, promising to be more GDPR compliant and also taking the chance to introduce a set of new features and concepts. At the same time, the beloved (but remember - still illegal) Universal Analytics was discontinued (and will be shut off in 2023).
After this rather long introduction - what's wrong with Google Analytics 4 then. If it's a GDPR compliant Universal Analytics replacement - which was beloved - why not using GA4?
Well - because Google changed almost any aspect of the software. Getting started is much more complex, the session-based tracking was replaced with event-based tracking (which is good for experts, but bad for beginners) and overall, beginners were obviously not the target group anymore. So does Google Analytics 4 work for experts? Unfortunately, it doesn't:
- Too much "magic" is still happening in the data model. Some numbers are just not comprehensible
- There is too little control over the captured events - when are they stored where, and how are they processed?
- Google Analytics 4 still tracks less events than eg. Snowplow. Reasons for that are unknown - but when directly comparing snowplow tracking and GA4 tracking - with Snowplow there are more users logged. A deep investigation of a team I led found that indeed the Snowplow-Tracking was much closer to the real user number than GA4 - by almost 10%
So - all of the above issues would not matter if GA4 was still a product for beginners - but it isn't anymore. And for experts - these issues are actually a dealbreaker. So no matter whether you are a beginner or expert - you will encounter huge flaws.
(Google tried to server both groups here - and let's be honest - when was there ever a product which served beginners and experts alike?)
While above issues are already big enough - there is one additional elephant in the room: Google Analytics 4 is still not GDPR compliant. It allows for more options to be closer to compliance than UA - however it still sends plain-text IP-Addresses to America and it is still unknown which user identifiable information is stored in which locations. Again - we have a problem here.
For me personally, it's not only the product issue or the fact that basically running GA4 is illegal - it's mainly the fact that I as a website owner want to respect my users privacy (by at the same time knowing what my site does good or bad). Using GA4 currently simply tells the user, that one does not respect them. As easy as that.
What is Snowplow?
Snowplow markets itself as "Behavioral Data Platform" - a platform for collecting and modelling user behavior. They see themselves as puzzle in a broader data strategy.
 Snowplow Marketing Slide
Snowplow Marketing Slide
While I like their approach and their overall marketing strategy is sound - in real-world terms, Snowplow is "simply" a web, mobile and app tracking solution - very good one, should be added. It generates data on user interaction (eg. when a user visits a page, clicks a button, etc.) and sends these data to a backend pipeline - hosted by you. This pipeline provides means for enriching your data - eg. to anonymize the data or adding more details from other data sources. And finally, the data is inserted in a data store of your choosing. Currently supported data targets are:
- Google BigQuery
- Snowflake
- Postgres
- AWS Redshift
- Databricks
To summarize: Snowplow collects data and provides tools to manage and enrich these data and store them in a database or data warehouse.
What's the architecture of Snowplow
Snowplow consists of two main components:
- The snowplow tracker
- The snowplow pipeline
The snowplow tracker
To create the behavioral data, snowplow utilizes a whole armada of tracking solutions, for all sorts of programming languages and use cases. Among others, there are trackers for:
- Javascript
- Native mobile
- .NET
- Java
- Go
- Python
- C++
and even Unity (the game engine)
For a full list, see the official docu.
Adding trackers is as easy as it gets, simply follow the instructions in the above linked documentation and you should be able to collect data within some minutes.
The Snowplow pipeline
The pipeline itself is actually the "heart" of snowplow. The pipeline is the place where most of the advantages of snowplow over any other tracking solution emerges.
The architecture of the snowplow pipeline is not independent of the cloud you are running. While it is possible to run snowplow on premise - it is a much more complex. For the sake of this blog, let's assume we run on the Google Cloud Platform (GCP). The situation is very similar for AWS.
When running the pipeline on GCP, it is comprised of the following components:
-
Collector server: The entry point of the pipeline. It provides an HTTP server, where the trackers send their data to.
-
Enrich server: All collected events are redirected to the enrich server. This component checks the validity of the data (more on that later), anonymizes them, adds additional enrichment (eg. it can look up information about the browser which sent the data and add these information to the data stream) and redirects the data to the database loader
-
Database loader: The database loader component is responsible for inserting the collected events into the selected database. Depending on the database, this component differs a bit. For example, running on Google BigQuery, this component consists of three sub-components:
- Streamloader: The streamloader inserts the events in the BigQuery data warehouse
- Mutator: The mutator is an ingenious small tool, simply checking the incoming datastream for unknown data points. If unknown data arrives, it automatically checks for validity. If the data are valid, the mutator adds the corresponding column to BigQuery. Therefore, if you add additional tracking data you are not obliged to manually add them to the BigQuery schema.
- Repeater: The repeater simply retries failed inserts - mainly because the mutator might take some time to create new database columns - therefore the repeater waits a some time (15 minutes by default) and then attempts to re-insert the events
-
Pub/Sub: The "glue" between all the above mentioned components is the Google Pub/Sub service. Pub/Sub is a managed message queue. The collector server sends it's data to a pub/sub topic, the enrich server then subscribes to this topic. The enrich server sends his enriched data to a different topic, which again is subscribed to by the database loader. Using pub/sub here provides some huge advantages. Mainly, it fully decouples all the components. Let's say the enrich server is overloaded - if the collector server would directly send the data to the enrich server we would most probably lose data. However, as the collector server simply publishes it's messages to pub/sub, the messages will be queued until the enrich server is able to handle them again.
Furthermore, we can also easily do pipeline maintenance tasks - even shutting down the whole pipeline - as long as at least one of our collector servers is running we will not lose a single event - as pub/sub will happily buffer our data.
Iglu - the snowplow schema registry
Snowplow does not simply accept all messages - you need to create a schema first. This ensures highest data quality - and after some getting used to, this really is a huge daily-life-improvement. In contrast to many other tracking tools, with Snowplow you have by definition a much higher data quality due to this restrictive event schemas.
Snowplow provides a tool called "Iglu" which acts as schema registry. It's a simply http server which reads the created schema either from static html file or from an Postgres server.
The enrich server then requests the schemas from the iglu server and then validates all incoming messages against this schema.
On a GCP snowplow installation, the Iglu-Server again is a simple compute instance (virtual machine) and a Postgres database running somewhere in reach of the server.
Failed and invalid messages
In addition to the already described pub/sub-topics, there are two more of them. They are used by all components: Failed inserts and bad rows. So, if the pipeline determines, that your messages are invalid, because they are ill-formed or do not conform to a schema, they will not be discarded - they will be sent to the bad-rows pub/sub topic. You can then use this topic to insert the data automatically into a GCS cloud blob storage - for further analyses - and even more important to maybe adjust your schema, transform the failed data and attempt to re-insert them. So you again decrease the likelihood of message loss.
Horizontal scaling and architecture summary
One thing to mention is the perfect execution of the Snowplow development team when it comes to horizontal scaling. All the above components can be run multiple times and linearly scale with the number of instances running. If your enrich server is too slow, simply add a second one with the same configuration - and you will have twice the throughput. The same goes for any of the other components.
The pipeline for GCP in summary looks as follows:
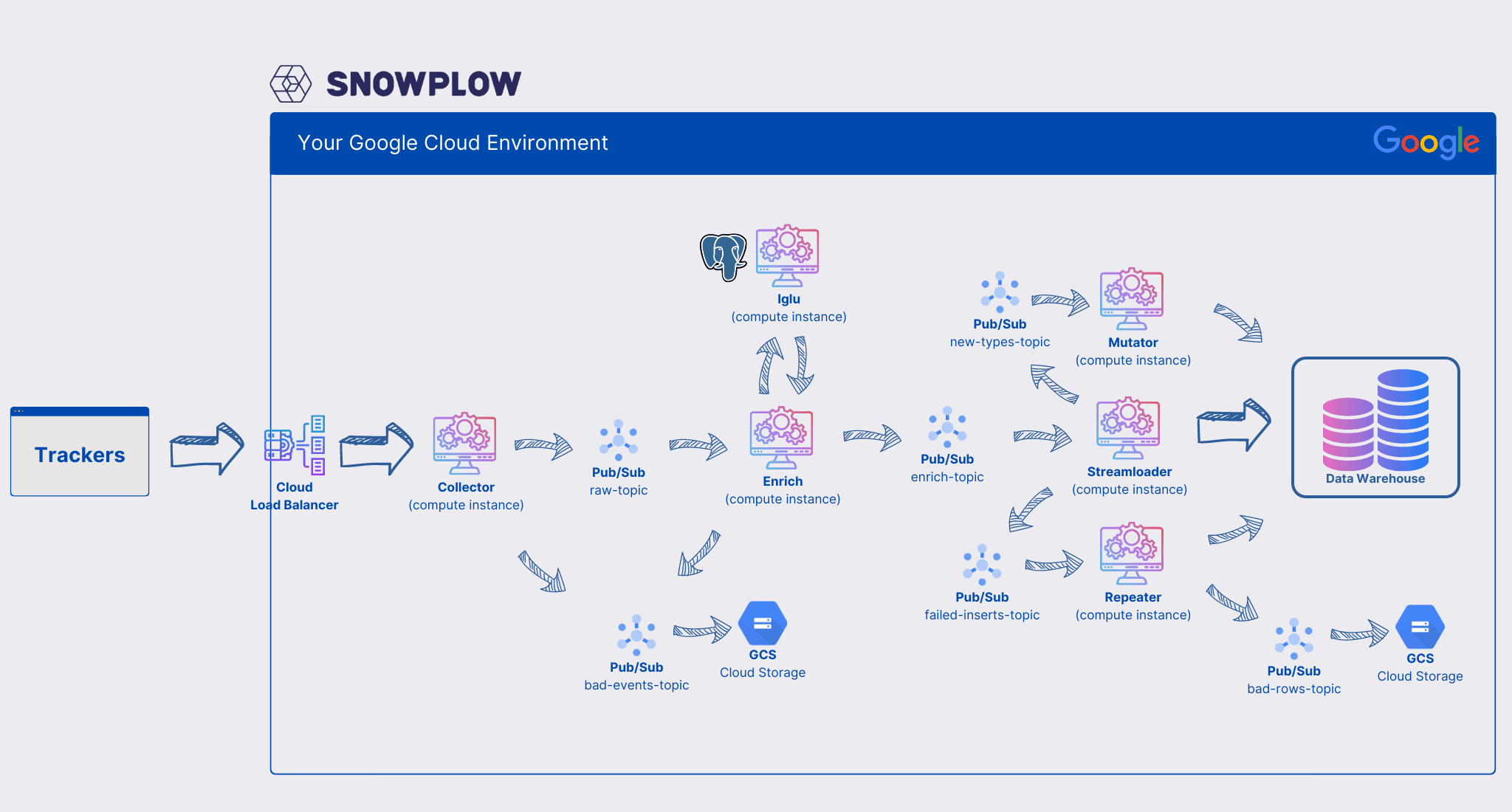 Snowplow architecture on GCP
Snowplow architecture on GCP
As you might see there are quite a few components involved when running Snowplow. However, this very loosely coupled infrastructure setup makes maintaining the pipeline rather easy.
(For more details on how the pipeline looks an AWS, have a look at their AWS quickstart)
Data modelling
The collected data with Snowplow are raw event data - meaning per event you get one entry in your data warehouse, containing all the collected parameters.
To make use of these data, it is suggested to model these raw data into the data model you need. As Snowplow is most prominently used for web-tracking, they provide out of the box data models for web and mobile tracking, to be found on their excellent docu page. The available models for web-tracking for example create models for:
- pageviews
- users
- and sessions
from the raw data - covering huge amounts of use-cases out of the box.
Feature summary
Now that we know what Snowplow is and what exactly this means infrastructure-wise, what are some of the most prominent features of Snowplow?
- The snowplow tracking can be done in accordance to GDPR and with user privacy in mind
- A lot of trackers for various programming languages available
- Very low latency - below 1 second from event-tracking to streamloader
- Event schemas lead to high data quality
- Decoupled architecture allows for easy scalability and pipeline operation
- Very good enrichment engine. Allows to add all sorts of context to your data
- Huge and very good data models - this helps with analyzing the data
- Full control over any step in the data pipeline
All in all, Snowplow is currently my favorite user behavior tracking solution. First of all, it is one of the only tools I can guarantee that it's GDPR compliant. The "no-magic" approach to pipelining and data modelling helps to understand your user in much more details compared to similar solutions. And having high-quality raw data sometimes is the only dream a data expert has - Snowplow delivers perfectly with this aspect.
------------------
Interested in how to train your very own Large Language Model?
We prepared a well-researched guide for how to use the latest advancements in Open Source technology to fine-tune your own LLM. This has many advantages like:
- Cost control
- Data privacy
- Excellent performance - adjusted specifically for your intended use