How to rent a 80 GB memory GPU without blowing your wallet?

Did you know that working with new and powerful Large Language Models (LLMs) - if you want to run and train your own - often requires powerful GPUs boasting up to 80GB of memory? Why is this so, one might wonder. Well, each LLM consists of Billions of parameters - basically numbers which determine the behavior of the model. And these billions of parameters need to be stored somewhere. Somewhere fast. Enter your GPU memory.
Sometimes, a single GPU, no matter how powerful, simply isn't enough to shoulder the extraordinary demands of our models. Thankfully, Large language models training can be distributed across multiple GPUs to house larger models and also shrink the training times substantially. Streamlining this process is key to staying ahead in a field characterized by perpetual urgency and innovation.
Understanding this, you may now ask, "But where do I get these high-performance GPUs from?". Well - easy. Go to Amazon and buy 2 NVIDIA A100 GPUs for $7.000 each... But wait... there's actually a less budget-blowing method: GPU on-demand.
That, dear readers, is where RunPod comes into play.
RunPod is a brilliant service that bridges the gap between users and high-tech resources. It offers cost-effective, easy-to-setup virtual machines furnished with single or multiple state-of-the-art GPUs. From higher-end consumer GPUs like NVIDIA RTX 3080s up to multiple NVIDIA A100s with 80GB of RAM each.
Imagine having access to an array of powerful GPUs to meet all your LLM training needs, without the substantial investment in hardware or the worries about maintenance or upgrades.
In this blog post, we will guide you through the process of acquiring these GPUs through RunPod and we'll also have a look at their real-world costs and how to actively manage your budget. Let's dive right in.
Why do we need GPUs and large amounts of VRAM for LLM training?
When it comes to training deep learning models, performance and speed are paramount. Not because you desperately need to be finished extremely fast, but because these models got so complex - with billions of parameters - that you need as much performance as possible during training to finish in a lifetime.
GPUs excel at parallel processing, allowing them to perform vast numbers of computations simultaneously. Modern deep learning frameworks leverage this parallelism to distribute the workload across GPUs, dramatically accelerating model training times. By utilizing the vast computational power of GPUs, training deep learning and large language models becomes significantly faster and more efficient.
Modern GPUs additionally provide specific cores just for AI operations - basically tuned for being extremely fast for the mathematical operations using for AI applications.
And then there is requirement for VRAM - the GPUs memory. Large language models consist of millions, and nowadays billions, of learnable parameters. These parameters store the "knowledge" of the model and are adjusted during training to optimize performance. To accommodate these vast parameter sets, ample VRAM is necessary. Each parameter requires memory to store and manipulate, and insufficient GPU VRAM can get a huge bottleneck.
Where to get CPUs for LLM model training?
There are actually several options where to get your GPUs:
-
Google Colab: Provided by Google, Colab is a platform to run Jupyter Notebooks. The platform provides quite beefy hardware - for FREE or for 10$/month if we need even better HW and RM. The free plan offers a NVIDIA T4 GPU with 12 GB of RAM which already suffices to train some of the 7 Billion parameter models. For larger models you need the paid plan for $10/month. This already offers GPUs up to 80GB of RAM. The drawbacks are quite low availability for these larger GPUs and that you can't interact with the underlying virtual machine - you just have a jupyter notebook interface.
-
Cloud Providers: It goes without mention that all the big cloud providers Azure, GCP and AWS provide GPU machines. Refer to their virtual machine pages for more details. For model training, they are a little behind solutions like Colab and RunPod as the setup process is more complex and you potentially don't require the machine to run for longer than some days - at least for model training.
-
On-Premise: Well, the most classical solution is to purchase the GPU and run it in your home and company. While this might require significant investments at first (a NVIDIA RTX 3080 which is considered the bare minimum for real LLM operations, still is around $1000 and an A100 is currently at around $4000), this might be worthwhile, if you plan to run many training operations. Considering you really need 24/7 model training, a service like RunPod (coming to that in a second) will cost up to $1500 for a single GPU! So in less than 4 months, your GPU purchase of an A100 would be amortized. But still keep in mind that for most operations, the training process will only require a day or two of a powered up GPU - this makes on-premise economically less attractive than on-demand services
-
RunPod: RunPod is an on-demand GPU provider, offering many NVIDIA GPUs for very attractive, hourly prices. Starting a GPU enabled virtual machine is as easy as pressing the Run button. You'll get SSH access, a quite versatile web-console and the jupyter server pre-installed. While nothing beats the Google Colab FREE pricing, the quite low hourly prices for GPUs and the ease of use make RunPod ideal for training, testing and experimenting.
While all 4 of the above options are worth considering - and the right choice under some circumstances - we at DSE found RunPod to be the best option for most use cases.
What is RunPod?
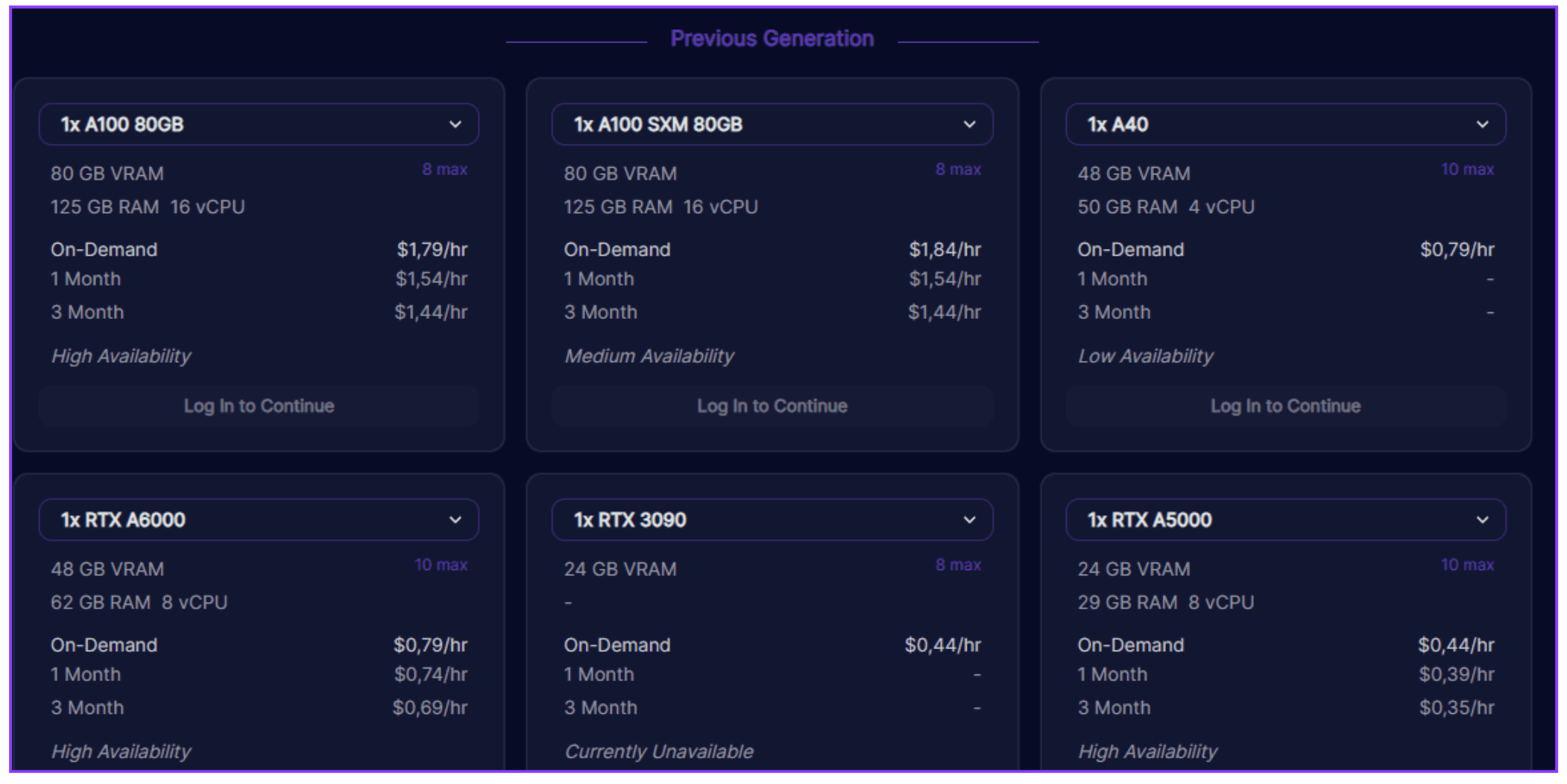
RunPod is a cloud-based service that provides scalable GPU infrastructure for production. It allows users to rent cloud GPUs starting from $0.2 per hour. The platform offers container-based GPU instances that can be deployed in seconds using both public and private repositories. It also provides serverless GPU computing on a pay-per-second basis, which brings autoscaling to production, low cold-start, and security using their secure cloud.
 RunPod GPU selection
RunPod GPU selection
RunPod also offers fully managed and scaled AI endpoints for various workloads. These endpoints are used for services like Dreambooth, Stable Diffusion, Whisper, and more. The platform provides free bandwidth and a range of GPU options with different capacities and pricing.
The service is divided into two types of clouds: the Community Cloud, which offers vetted hosts, many compute options, and rock-bottom pricing; and the Secure Cloud, which operates from Tier 3/4 data-centers, provides dedicated bandwidth, failover/redundancy, strict privacy & security, and uses enterprise-grade hardware.
As for what you get when you rent a GPU: RunPod will spawn a docker container with on-demand access to the GPUs you selected.
How to rent a GPU using RunPod?
Ok, theory done, let's dive into action.
-
Navigate to RunPod.io and create an account.
-
After being logged in, you need to first buy some credits. So RunPod does not provision their GPUs if you don't have some money transferred first. It works kind of like a mobile phone prepaid card. Navigate to "Billing", enter the desired amount (I suggest to start with as low as $10 for testing the waters) and hit "Pay with Card".
 RunPod billing. After entering your credit card details, you are ready to go.
RunPod billing. After entering your credit card details, you are ready to go. -
Navigate to "Community Cloud" for the cheaper options and "Secure cloud" for the more expensive options.
- Secure Cloud runs in T4 data centers by RunPod trusted partners. They come with high-reliability, redundancy, security, and fast response times to mitigate any downtimes. For any sensitive and enterprise workloads, Secure Cloud is recommended.
- Community Cloud brings power in numbers and diversity spanning the whole world. Through RunPods decentralized platform, they can offer peer-to-peer GPU computing that connects individual compute providers to compute consumers. The Community Cloud hosts are invite-only and vetted by RunPod. Suggested for model training, testing and experimenting.
-
In the next screen, you can select the GPU you want to rent.
 RunPod GPU selection
RunPod GPU selectionClick on the arrow on the left side of the GPU names to not only rent on GPU, but a multi-GPU cluster with up to 8 GPUs. Click on "Deploy".
-
In the next screen, select your pod template. Templates determine which docker image will be used for your container. So basically it determines, which software and libraries are already preinstalled. For most ML and AI applications nowadays you are fine by selecting the pytorch 2.0.1 template.
 Select template screen
Select template screenNote: You get root access to the container spawned for you - so you might install additional software packages afterwards. You might even create your very own template.
Make sure to tick "Start Jupyter Notebook" to get a Jupyter environment set up for you. Very convenient.
-
Optional: By clicking "Customize deployment" you can change the disk sizes, exposed ports as well as docker command to run when starting your container.
 Customize Deployment
Customize Deployment -
Click on
Continueand thenDeploy. Your pod will be provisioned. RunPod provisioning screen
RunPod provisioning screen -
Next you are automatically redirected to your new pod (VM). Click on the arrow at the top right and then "Connect" to find your connection options.
 RunPod pods overview
RunPod pods overview RunPod connection options
RunPod connection optionsHere you can access the very versatile web terminal or Jupyter lab. Simply click on "Connect to Jupyter Lab" and your preinstalled jupyter environment is presented.
 RunPod Jupyter Lab
RunPod Jupyter Lab
That's it - you successfully provisioned a pod with one or multiple powerful GPUs - ready to tackle huge AI workloads. With the connection options presented above, your pod acts similar to a virtual machine. Just keep in mind, everything which is not in the /workspace folder will be deleted when you stop your pod - so keep all your persistent files in /workspace.
How to manage costs with RunPod?
The general cost structure on RunPod is as follows:
- You pay an hourly rate per GPU, starting from $0.2. See this pricing chart for the current rates. You only pay, if your pod is running. Stopped pods are not charged.
- You pay $0.10/GB/Month for storage for running pods and $0.20/GB/Month for powered down pods.
- No bandwidth costs (this is incredible - compared to eg. cloud providers)
- RunPod provides Savings Plans. Savings plans are a way for you to pay up-front and get a discount for it. This is great for when you know you will need prolonged access to compute. You can learn more on the about Savings Plans here. You can save up to 50% if you prepay for 3 months. Yes - that's right. Compared to big cloud providers where you need to reserver for years and years to come, RunPod saves you big bucks if you only commit for either 1 or 3 months!
Additionally to these on-demand features, there is a Serverless option - meaning you pay per second and get autoscaling out of the box. This is a highly valuable service for model inference scenarios - especially when starting out. Imagine having 3 to 10 requests per hour and you need to buy or rent a full GPU for that? With this serverless option you get a really affordable way of running your operations.
Taking all of that into considerations, we can manage our costs as follows:
- Don't over-provision your storage. Think about how much storage you need and choose this amount during pod creation
- Stop pods when you don't need them. Consider using their API found here to create automatic pod start and stop schedules
- Use a cost savings plan. This is almost a no-brainer as you only need to commit to 1 month and already get significant savings.
- Use the serverless option after model training for model inference.
Summary
In conclusion, training Large Language Models (LLMs) requires significant computational resources, particularly GPUs, due to the vast amount of data they need to process. GPUs are designed to handle parallel operations efficiently, making them ideal for the matrix operations and high-speed computations required in machine learning and deep learning tasks. However, acquiring and maintaining a fleet of high-performance GPUs can be prohibitively expensive and complex, especially for small teams or individual researchers.
This is where RunPod comes into play. RunPod is a cloud-based service that provides scalable GPU infrastructure specifically designed for high-performance computing tasks like training LLMs. With RunPod, you can rent cloud GPUs starting from as low as $0.2 per hour, making it a cost-effective solution for those who need high-performance computing resources but don't have the capacity to maintain their own hardware.
RunPod offers a range of GPU options with different capacities and pricing, allowing you to choose the one that best fits your needs. It also provides serverless GPU computing on a pay-per-second basis, bringing autoscaling to production, low cold-start, and security using their secure cloud.
As we've seen in this guide, setting up and operating even a cluster of GPUs is easy and straight forward. Utilizing either Autoscaling or actively managing the GPU fleet makes sure to keep budget under control.
Note: Some of the links in this blog are RunPod affiliate links, earning me a small commission if you sign up. If you don't want this, simply directly navigate to runpod.io without clicking my links.
What's next?
If you want to use Language Models to chat with your BigQuery data, have a look at this next post.
If you are more interested in how to connect your very own pdf files to GPT and ask questions about them, have a look at my LangChain PDF tutorial
And if you are interested in how to utilize GPT-3.5/4 to automate your data analytics, have a look at this csv analytics guide
------------------
Interested in how to train your very own Large Language Model?
We prepared a well-researched guide for how to use the latest advancements in Open Source technology to fine-tune your own LLM. This has many advantages like:
- Cost control
- Data privacy
- Excellent performance - adjusted specifically for your intended use